Table of Contents
Data Structures And Algorithm Notes
Data Structures
- Data Structures - Overview
- Heap (Wikipedia)
Algorithms
- Search algorithm (Wikipedia)
- Sorting algorithm (Wikipedia)
- NP-complete (Wikipedia)
- Travelling salesman problem (Wikipedia)
- Knapsack problem (Wikipedia)
- Graph theory (Wikipedia)
- Breadth-first search (Wikipedia)
- Depth-first search (Wikipedia)
Big-O Notation
Questions and Topics
Q. Bitwise Operations and Bitwise AND, OR, XOR and NOT Operators and Bit Masks
NOT - Bits that are 0 become 1, and those that are 1 become 0. Used to unset/turn off bit flags. AND - Multiplication of bits; i.e., 1 × 0 = 0 and 1 × 1 = 1. Used to check state of a bit flag. OR - 1 if either bit is 1, otherwise 0. Used to set/turn on bit flags regardless of whether already on or not. XOR - 1 if both bits are different, 0 if they are the same. Used to toggle flag bits of a mask. Arithmetic Shifts: left << (multiplies by 2, 0 shifted on as least significant bit), right >> (divides by 2, left-most sign bit is retained) Logical Shift: right >>> (divides by 2, 0 shifted on as most significant bit)
Q. What's the difference between a LinkedList and an ArrayList (or between a linked list and an array/vector)?
An ArrayList is a List implementation backed by a Java array. With a LinkedList, the List implementation is backed by a doubly linked list data structure.
Q. How can you detect a cycle in a linked list?
Turtle and Rabbit: The idea is to have two references to the list and move them at different speeds. Move one forward by 1 node and the other by 2 nodes. If the linked list has a loop they will meet. If there is no loop either of the references will become null when it reaches the end of the list. O(n)
Q. What is a weighted round robin load balancing algorithm?
Round robin distribution is used by DNS servers, peer-to-peer networks, and many other multiple-node clusters/networks. In a weighted round-robin algorithm, each destination (in this case, server) is assigned a value that signifies, relative to the other servers in the list, how that server performs. This "weight" determines how many more (or fewer) requests are sent that server's way; compared to the other servers on the list.

root, children (enqueue/add), children of children (dequeue/remove first and enqueue), etc... Use a fifo queue Typical applications: - Shortest path between two vertices.
public class BreadthFirstPaths {
private boolean[] marked;
private int[] edgeTo;
...
private void bfs(Graph G, int s) {
Queue<Integer> q = new Queue<Integer>();
q.enqueue(s);
marked[s] = true;
while (!q.isEmpty()) {
int v = q.dequeue();
for (int w : G.adj(v)) {
if (!marked[w]) {
q.enqueue(w);
marked[w] = true;
edgeTo[w] = v;
}
}
}
}
}

root, children (push) to leaf nodes, left, then up (pop) and right... Use a stack
+
3 4
preorder/prefix (Polish notation, e.g. + 3 4), postorder/postfix (reverse Polish notation, e.g. 3 4 +),
inorder/infix (e.g. 3 + 4) - expression tree
Recursive algorithm.
Typical applications:
- Find all vertices connected to a given source vertex.
- Find a path between two vertices.
After DFS, should be able to:
- Find vertices connected to root/source in constant time
- Find a path back to root/source in time proportional to its length
public class DepthFirstPaths {
private boolean[] marked;
private int[] edgeTo;
private int s;
public DepthFirstSearch(Graph G, int s) {
...
dfs(G, s);
}
private void dfs(Graph G, int v) {
marked[v] = true;
for (int w : G.adj(v))
if (!marked[w]) {
dfs(G, w);
edgeTo[w] = v;
}
}
}
Q. Name some self balancing binary trees
Red/black tree, splay tree, AVL tree
Q. What is Big-O Notation?
Defines worst case performance of an algorithm (ex: O(N)). There is also Omega (best case - ex: Ω(N)) and Theta (average case - ex: Θ(N)). Given N we might have, N, N log N, N^2 performance, for example.
Q. Merge sort
Split in 2, recurse left, recurse right, merge sorted halves. Can be "stable" - i.e. retains existing sorts if order of equal items is not changed, and no long distance exchanges are made. Java sorts Objects with a merge sort algorithm. N log N.
public class MergeSort {
public static void sort(Object[] a, Comparator comparator) {
Object[] aux = new Object[a.length];
sort(a, aux, comparator, 0, a.length - 1);
}
private static void sort(Object[] a, Object[] aux, Comparator c, int lo, int hi) {
// Optimize sort for small subarrays (CUTOFF = 7 perhaps):
if (hi <= lo + CUTOFF - 1) {
Insertion.sort(a, c, lo, hi);
return;
}
int mid = lo + (hi - lo) / 2;
sort(a, aux, c, lo, mid);
sort(a, aux, c, mid + 1, hi);
// Optimize if already sorted:
if (!less(c, a[mid + 1], a[mid])) return;
merge(a, aux, c, lo, mid, hi);
}
private static void merge(Object[] a, Object[] aux, Comparator c, int lo, int mid, int hi) {
assert isSorted(a, c, lo, mid); // precondition: a[lo..mid] sorted
assert isSorted(a, c, mid + 1, hi); // precondition: a[mid+1..hi] sorted
// Copy to working array:
for (int k = lo; k <= hi; k++)
aux[k] = a[k];
// Merge two arrays:
int i = lo, j = mid + 1;
for (int k = lo; k <= hi; k++) {
if (i > mid) a[k] = aux[j++];
else if (j > hi) a[k] = aux[i++];
else if (less(c, aux[j], aux[i])) a[k] = aux[j++];
else a[k] = aux[i++];
}
assert isSorted(a, c, lo, hi); // postcondition: a[lo..hi] sorted
}
...
}
Q. Quick sort
Randomly shuffle array to prep process and avoid worst case comparisons (~1/2 * N^2) which becomes very unlikely to happen (if shuffle actually sorted the array!) Then pick a partitioning element as a divide/pivot point, less vs. greater, exchange elements that are out of place, recurse. Is not "stable". Faster than Merge sort because less movement of items even though more compares in average case. N log N. Too many duplicate keys can also affect efficiency. Java sorts primitive types with a quick sort algorithm.
public class QuickSort {
private static int partition(Comparable[] a, int lo, int hi) {
int i = lo, j = hi + 1;
while (true) {
while (less(a[++i], a[lo])) // find item on left to swap
if (i == hi) break;
while (less(a[lo], a[--j])) // find item on right to swap
if (j == lo) break;
if (i >= j) break; // check if pointers cross
exch(a, i, j); // swap items
}
exch(a, lo, j); // swap with partitioning item
return j; // return index of item now known to be in place
}
public static void sort(Comparable[] a) {
StdRandom.shuffle(a); // shuffle ensures performance is good
sort(a, 0, a.length - 1);
}
private static void sort(Comparable[] a, int lo, int hi) {
// Optimize sort for small subarrays (CUTOFF between 10 and 20):
if (hi <= lo + CUTOFF - 1) {
Insertion.sort(a, lo, hi);
return;
}
int j = partition(a, lo, hi);
sort(a, lo, j - 1);
sort(a, j + 1, hi);
}
}
Q. Sorting Summary
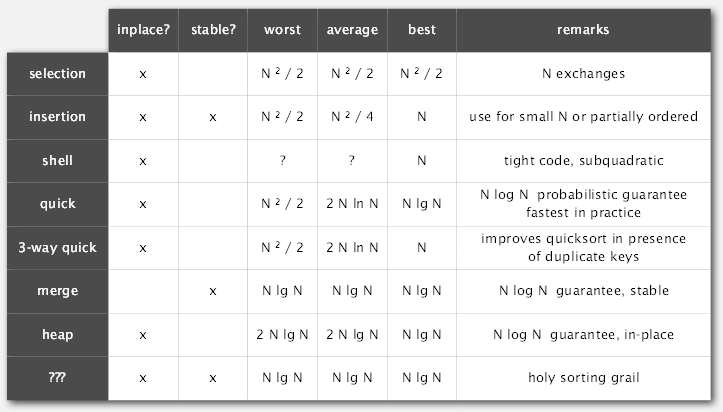
Q. Implement a hashtable (dictionary)
An array of linked lists, indexed by a hash, where hash collisions are placed in buckets in the linked list.
left subtree nodes < parent node <= right subtree nodes. Efficient for sorting, searching in-order.
public class BST<Key extends Comparable<Key>, Value> {
private Node root; // root of BST
private class Node {
private Key key; // sorted by key
private Value val; // associated data
private Node left, right; // left and right subtrees
public Node(Key key, Value val, int N) {
this.key = key;
this.val = val;
this.N = N;
}
}
// return value associated with the given key, or null if no such key exists
public Value get(Key key) {
return get(root, key);
}
private Value get(Node x, Key key) {
if (x == null) return null;
int cmp = key.compareTo(x.key);
if (cmp < 0) return get(x.left, key);
else if (cmp > 0) return get(x.right, key);
else return x.val;
}
/***********************************************************************
* Insert key-value pair into BST
* If key already exists, update with new value
***********************************************************************/
public void put(Key key, Value val) {
root = put(root, key, val);
}
private Node put(Node x, Key key, Value val) {
if (x == null) return new Node(key, val, 1);
int cmp = key.compareTo(x.key);
if (cmp < 0) x.left = put(x.left, key, val);
else if (cmp > 0) x.right = put(x.right, key, val);
else x.val = val;
return x;
}
}
Q. Heap (priority queue)
Complete binary tree (i.e. only bottom level might not be complete, left to right), heap ordered (i.e. parent values > children values)
Q. Graphs
trees with interconnecting nodes
Q. Graph algorithms, such as Dijkstra and A*
Best-first search is a search algorithm which explores a graph by expanding the most promising node chosen according to a specified rule. A* uses a best-first search and finds the least-cost path from a given initial node to one goal node (out of one or more possible goals). It uses a distance-plus-cost heuristic function (usually denoted f(x)) to determine the order in which the search visits nodes in the tree. Dijkstra's algorithm, conceived by Dutch computer scientist Edsger Dijkstra in 1959,[1] is a graph search algorithm that solves the single-source shortest path problem for a graph with nonnegative edge path costs, producing a shortest path tree. This algorithm is often used in routing.
Q. NP-complete problems, such as traveling salesman and the knapsack problem
Traveling Salesman problem: Given a list of cities and their pairwise distances, the task is to find a shortest possible tour that visits each city exactly once. Knapsack problem: Given a set of items, each with a weight and a value, determine the number of each item to include in a collection so that the total weight is less than a given limit and the total value is as large as possible.
Except where otherwise noted, content on this wiki is licensed under the following license: CC Attribution-Noncommercial-Share Alike 3.0 Unported